밑바닥부터 Kanana LLM 개발하기: Post-training
LLMPost-trainingKanana LLMSupervised Fine-tuningPreference-based learning한국어 성능
AI 요약
Beta카카오의 AI 모델 개발 조직인 카나나 알파(Kanana ⍺)에서 자체 개발한 Kanana LLM의 Post-training 과정을 상세히 설명하는 글입니다. Post-training은 Pre-training으로 얻은 방대한 지식을 바탕으로, 사용자의 명령을 더 잘 이해하고 따르도록 모델을 미세 조정하는 단계입니다.
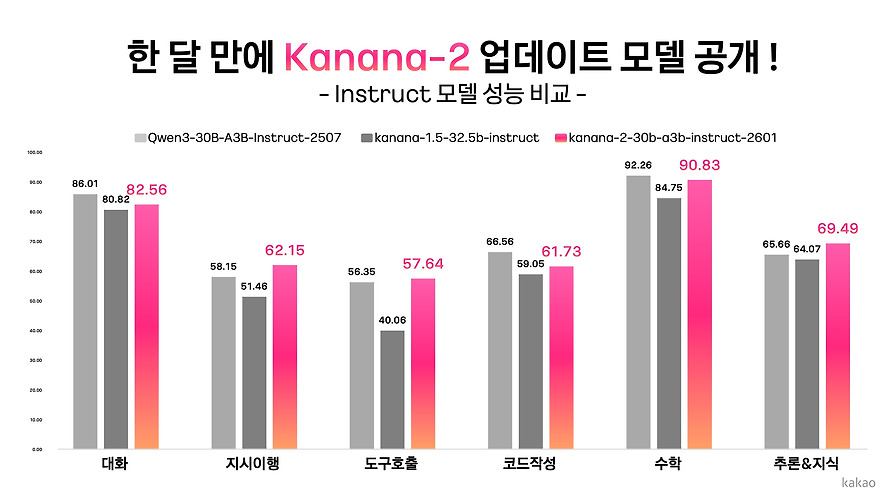
이 글에서는 Kanana Essence Instruct와 Kanana Nano Instruct 모델의 학습 과정과 성능 결과를 다루며, 특히 글로벌 SOTA 모델과 비교했을 때 동등한 영어 성능과 압도적인 한국어 성능을 달성했음을 강조합니다. Post-training의 개념과 일반적인 방식인 지도 학습 기반 미세 조정(SFT) 및 선호도 기반 학습(Preference-based learning)에 대한 개요를 제공합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기