Kanana-2 개발기 (1): Pre-training에서의 의사결정들을 중심으로
Kanana-2LLMMoEPre-trainingAI 모델대규모 언어 모델
AI 요약
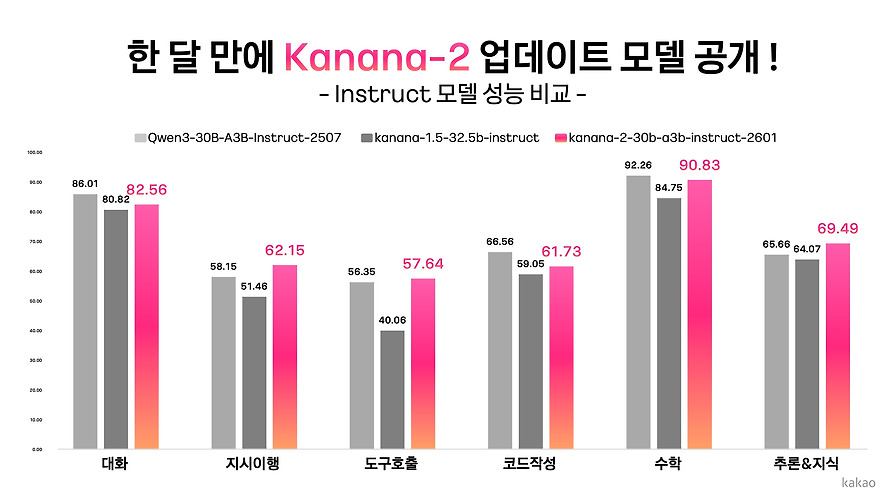
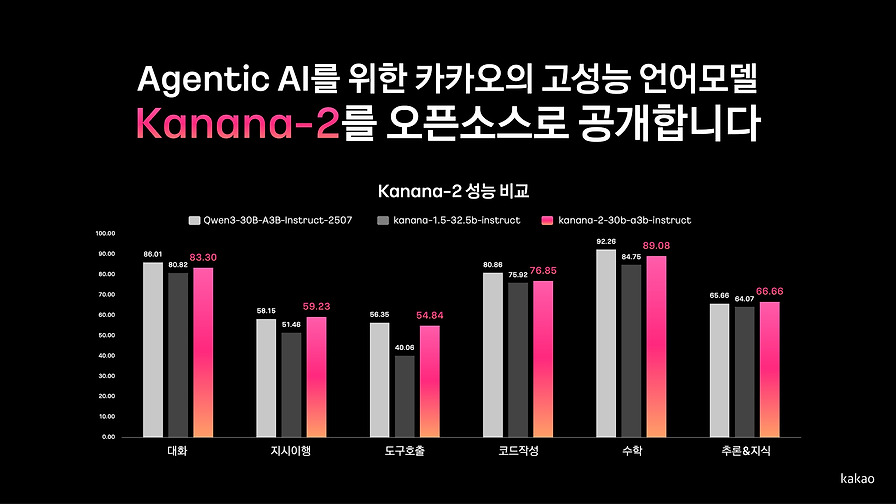
Beta카카오의 AI 모델 개발팀인 카나나 LLM 조직에서 개발한 차세대 언어 모델 Kanana-2의 개발 과정을 공유하는 글입니다. Kanana-2는 성능 향상과 비용 절감을 위해 전문가 혼합(MoE) 아키텍처를 채택하여, 거대 모델의 지능을 유지하면서도 추론 시에는 일부 파라미터만 활성화하여 연산 효율을 극대화했습니다.
직접 개발한 커널을 통해 학습 속도를 높이고 메모리 사용량을 줄여 고효율 저비용 모델을 완성했습니다. 현재 더 거대한 스케일의 Kanana-2-155b-a17b 모델을 학습 중이며, FP8 training을 위한 인프라 최적화, MuonClip, Hyperparameter Transfer 등의 기술 개발을 통해 대규모 훈련에서도 안정적인 성능을 달성했습니다.
이 글은 모델 자체뿐만 아니라 개발 과정에서의 고민과 해결 과정을 공유하는 데 중점을 둡니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기