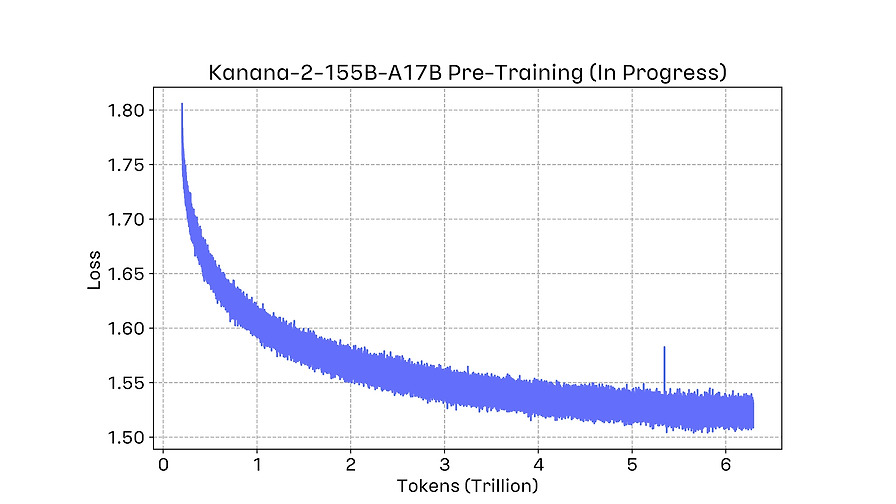
국내 최초 MoE 모델 ‘Kanana-MoE’ 개발기
MoELLMKananaMixture of Experts대규모 언어 모델카카오
AI 요약
Beta카카오의 AI 모델 개발팀이 국내 최초로 MoE(Mixture of Experts) 모델인 'Kanana-MoE' 개발 경험을 공유합니다. MoE는 LLM의 파라미터 수가 증가함에 따라 발생하는 연산 비용, 메모리 사용량, 학습 효율성 문제를 해결하기 위한 기술입니다.
5배 빠르며, expert 수가 많을수록 더 빨라집니다. 7B-A3B' 모델을 개발했으며, 이는 오픈소스로 공개되었습니다.
Dense 모델은 모든 파라미터가 연산에 참여하여 성능은 좋지만 연산량이 파라미터 규모에 비례해 증가하는 단점이 있어, MoE는 이러한 한계를 극복하는 효율적인 대안으로 주목받고 있습니다. 델을 개발했으며, 이는 오픈소스로 공개되었습니다. Dense 모델은 모든 파라미터가 연산에 참여하여 성능은 좋지만 연산량이 파라미터 규모에 비례해 증가하는 단점이 있어, MoE는 이러한 한계를 극복하는 효율적인 대안으로 주목받고 있습니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기