LINE 서비스의 대규모 광고 데이터를 처리하기 위한 Spark on Kubernetes 적용기
SparkKubernetesData PipelineBig DataHadoopLINE Ads
AI 요약
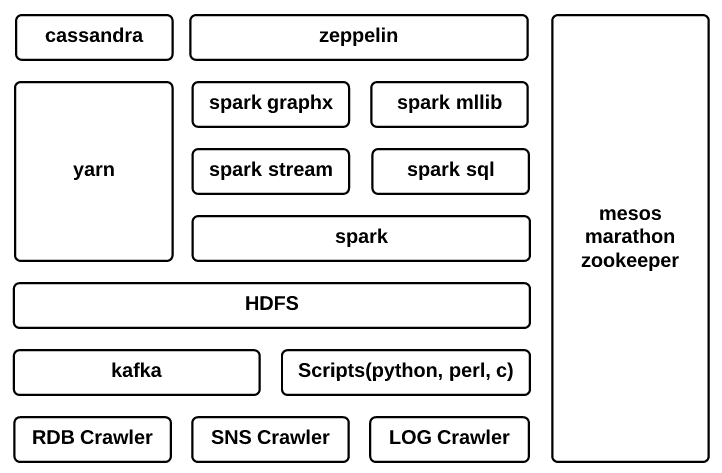
BetaLINE 광고 플랫폼은 하루 수십억 건 이상의 광고를 송출하고 천억 건에 준하는 데이터를 수집 및 가공합니다. 데이터 파이프라인 팀은 광고 효율 증대를 위해 실시간 데이터 처리, 가공, 저장, 전송 역할을 수행하며, 피처 증가로 인한 연산량 증가와 기존 Hadoop 기반 YARN 환경의 한계(자원 경합, 높은 운영 비용, 앱 의존성)를 겪고 있었습니다.
이러한 문제를 해결하기 위해 LINE은 인프라 독립성과 유연한 컨테이너 환경을 제공하는 Spark on Kubernetes를 도입했습니다. 이 글은 Spark on Kubernetes 도입 과정과 그 성과를 공유하며, 대규모 광고 데이터 처리를 위한 안정적이고 확장 가능한 데이터 파이프라인 구축의 중요성을 강조합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기