Spark on Kubernetes로 가자!
SparkKubernetesEMRYARN데이터 파이프라인Data LakeSelf-hosted
AI 요약
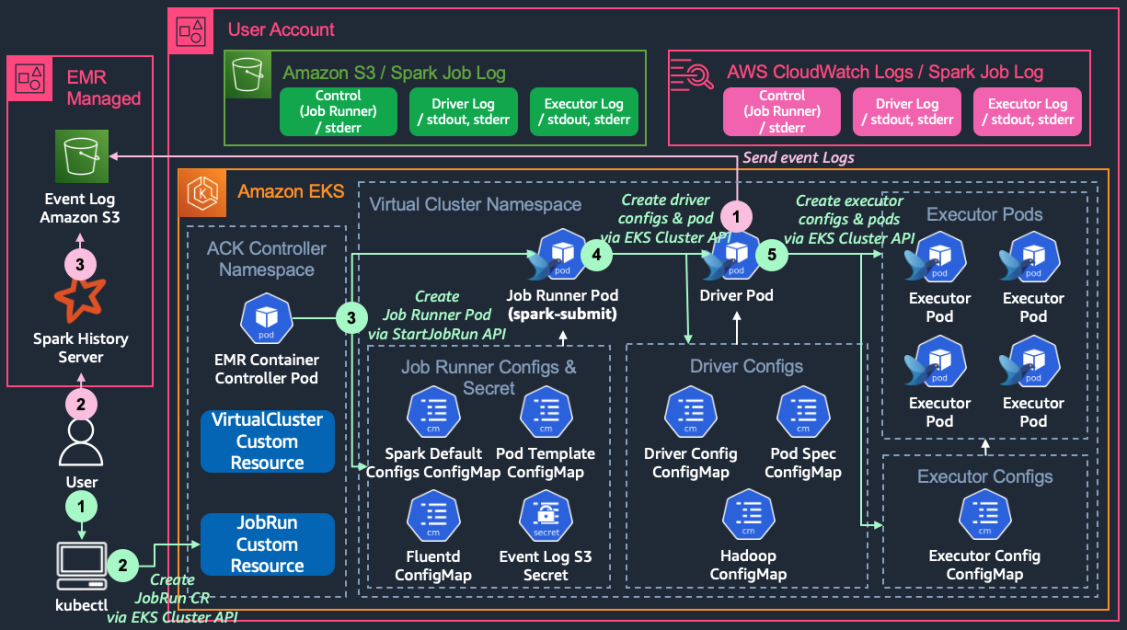
Beta뱅크샐러드 데이터 플랫폼 팀은 기존의 EMR, YARN 기반 Spark 환경을 Self-hosted Kubernetes 기반으로 전환한 경험을 공유합니다. 기존 환경에서는 EMR 클러스터 운영 중 발생하는 다양한 문제점과 세세한 설정의 어려움을 겪었습니다.
이 글은 이러한 문제점을 해결하고 데이터 분석 환경의 컴퓨팅을 Kubernetes로 이전하는 과정에서 얻은 인사이트를 제공합니다. 데이터 레이크 구축, Spark job 실행, 그리고 Kubernetes 환경에서의 효율적인 자원 관리 및 배포 전략에 대한 내용을 다룹니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기