Spark Shuffle Partition과 최적화
SparkPartitionShuffle Partition최적화데이터 처리분산 처리
AI 요약
Beta본 글은 카카오 데이터PE셀의 Logan님이 작성한 Spark Shuffle Partition 최적화에 대한 기술 블로그입니다. Spark의 핵심 개념인 Partition에 대한 이해를 돕고, 실제 최적화 실험을 통해 성능 향상 방안을 제시합니다.
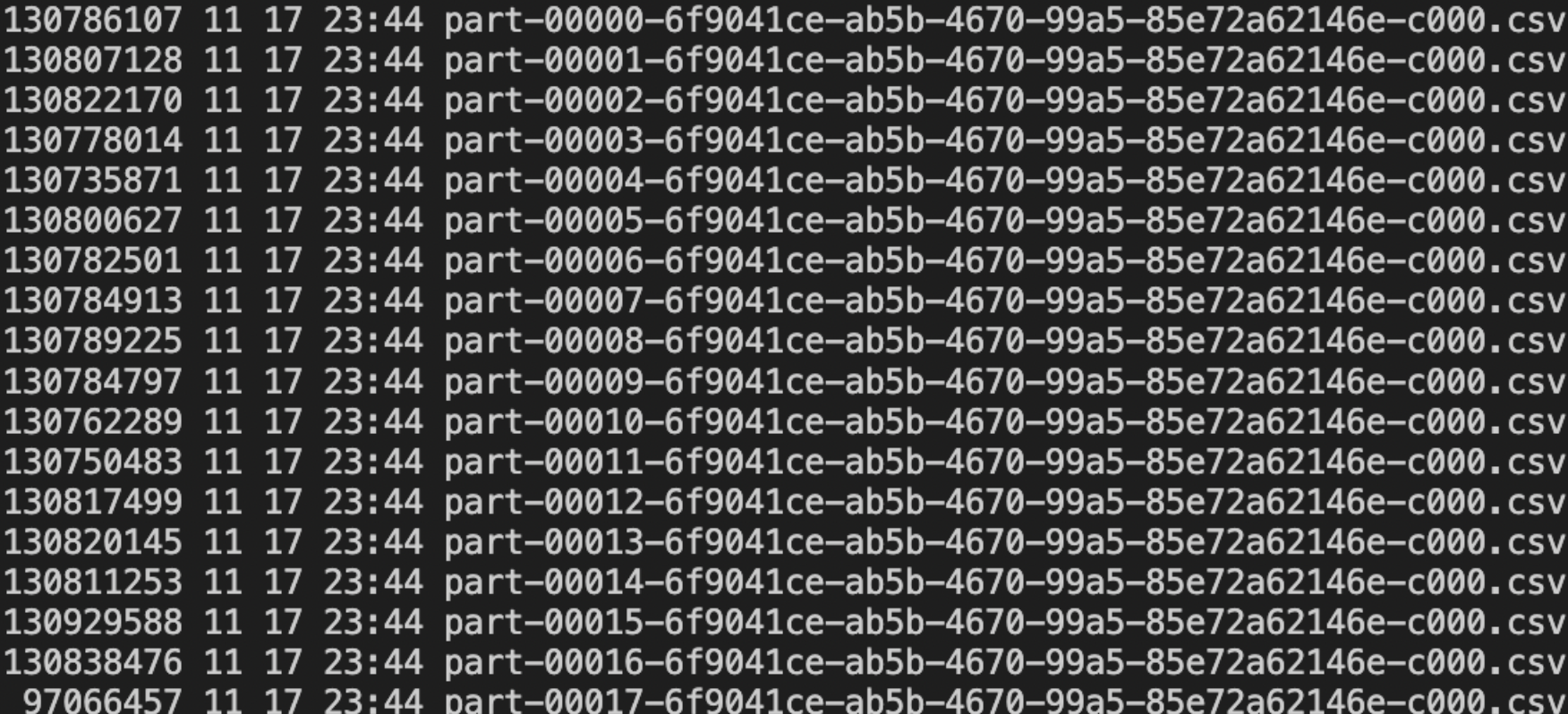
Partition은 RDDs나 Dataset를 구성하는 최소 단위로, 각 Partition은 다른 노드에서 분산 처리되며 하나의 Task는 하나의 Partition을 처리합니다. 즉, 1 Core = 1 Task = 1 Partition의 관계를 가집니다.
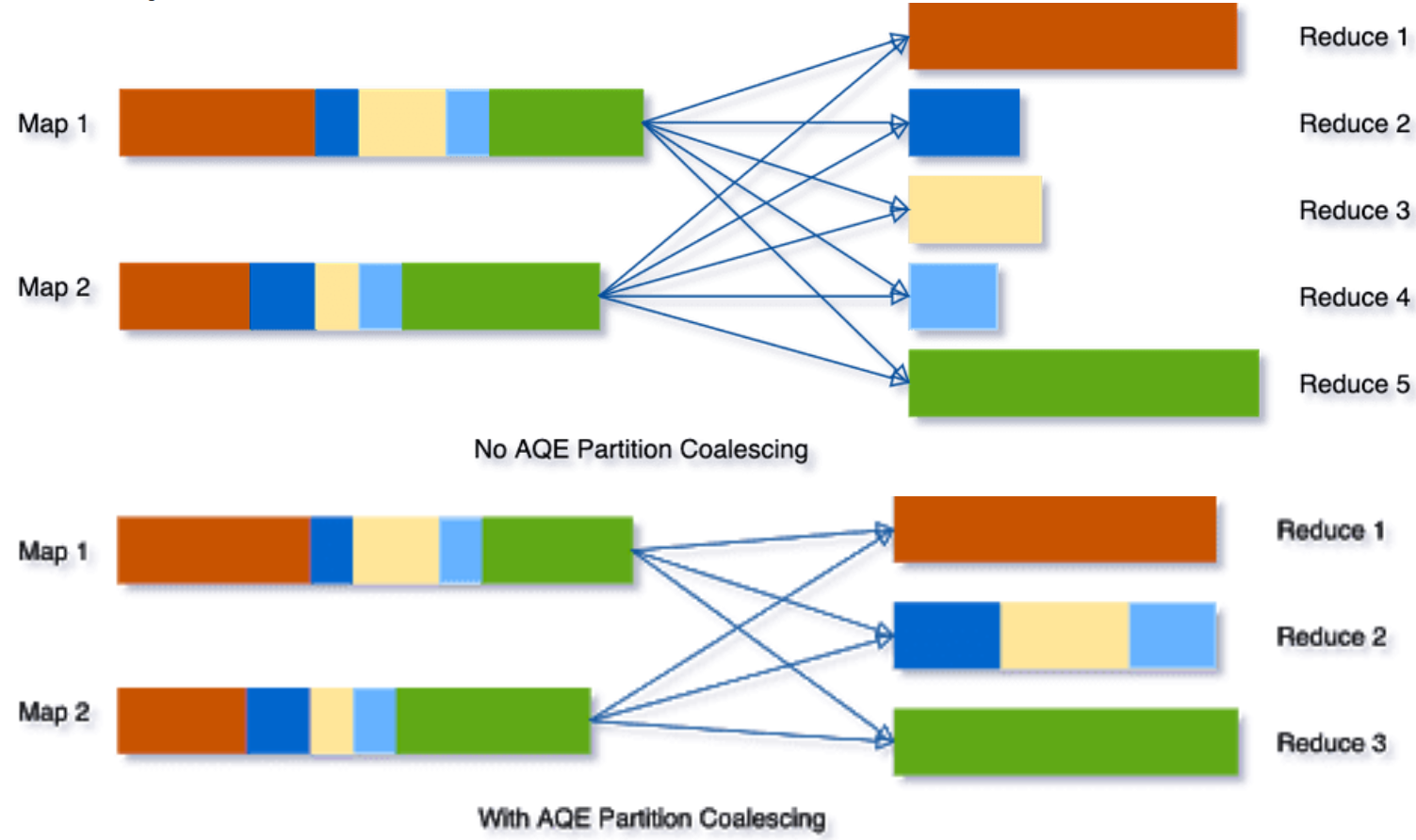
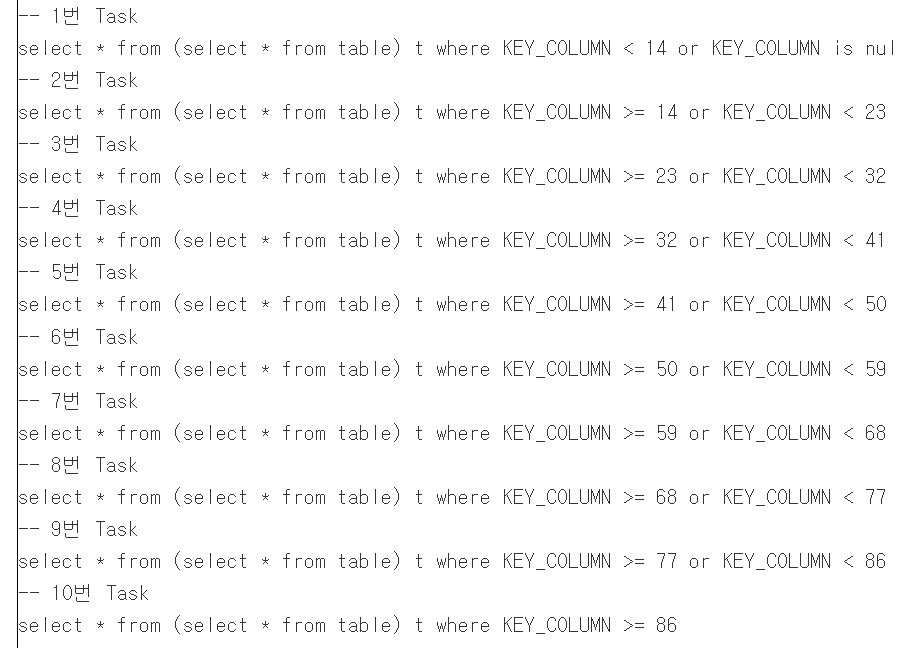
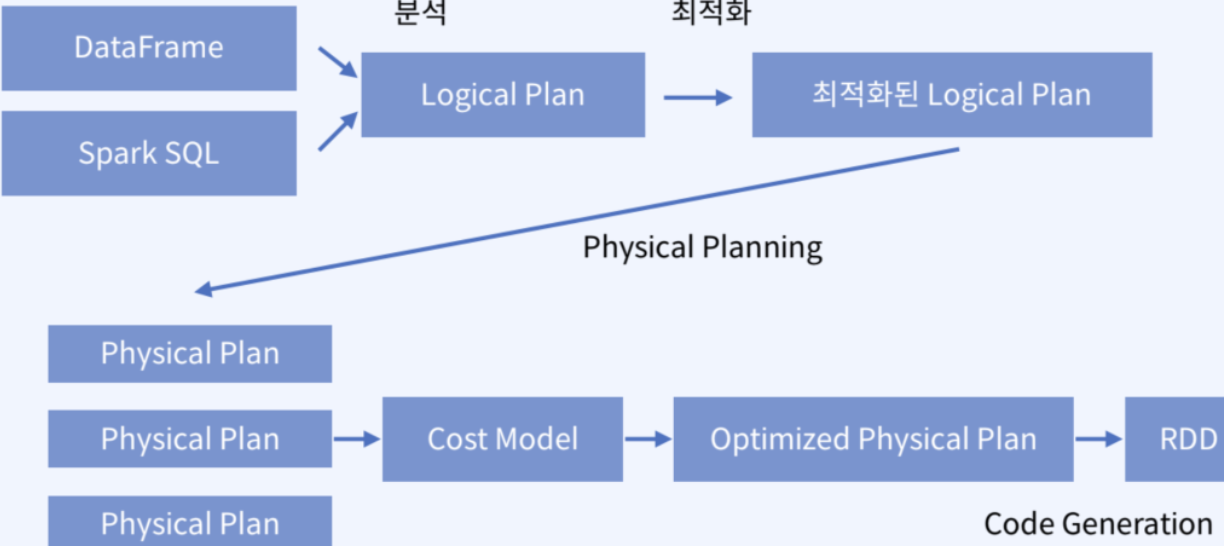
Partition의 수와 크기는 Spark 성능에 직접적인 영향을 미치며, Partition 수를 늘리면 Task 당 필요한 메모리가 줄고 병렬화 정도가 늘어납니다. 글에서는 Input Partition, Output Partition, Shuffle Partition의 세 가지 종류를 소개하며, 특히 Shuffle Partition 최적화에 초점을 맞춰 Spark의 효율적인 자원 활용 및 성능 개선 방법을 설명합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기