Spark 3편 – Optimize Partition
SparkPartitionOptimize데이터 처리Big DataPerformance Tuning
AI 요약
Beta이 글은 Apache Spark의 파티션 최적화에 대한 내용을 다룹니다. Spark은 대규모 데이터를 효율적으로 처리하기 위해 데이터를 파티션이라는 더 작은 단위로 분할하며, 파티션 수는 병렬 처리 정도를 결정합니다.
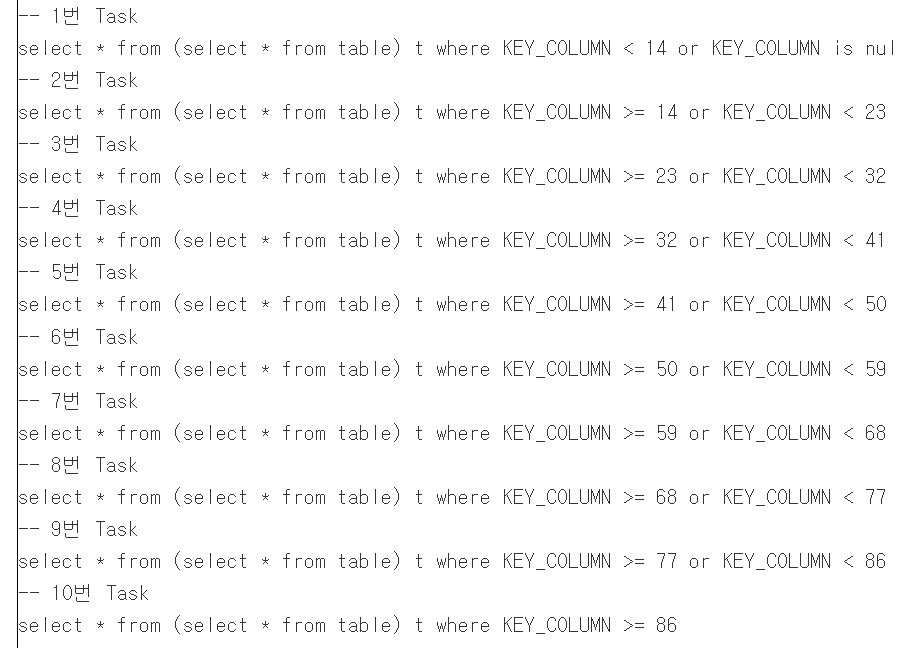
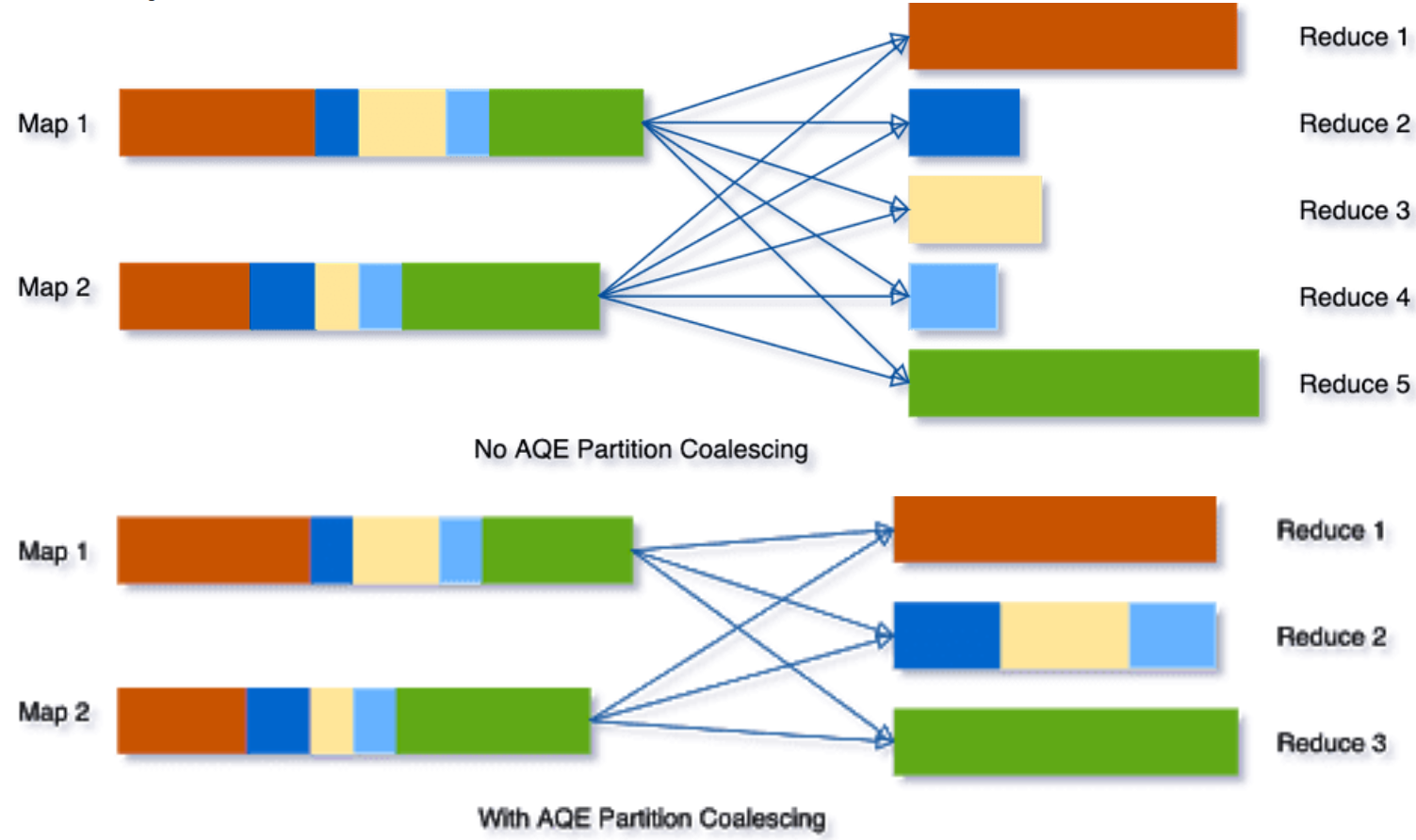
잘못된 파티션 활용은 데이터 왜곡(핫 파티션 발생)이나 컴퓨팅 파워 낭비와 같은 문제를 야기할 수 있습니다. 글에서는 파티션의 개념, 잘못된 활용 사례, 파티션 종류, 그리고 Output Partition과 Shuffle Partition에 대해 설명하며, Spark 작업의 성능을 향상시키기 위한 파티션 최적화의 중요성을 강조합니다.
특히, 데이터의 균등한 분배와 적절한 파티션 수 설정이 Spark 성능에 미치는 영향을 구체적인 예시와 함께 보여줍니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기