Spark 9편: JDBC 병렬처리 시 주의 사항
SparkJDBC병렬처리데이터 수집파티션데이터베이스
AI 요약
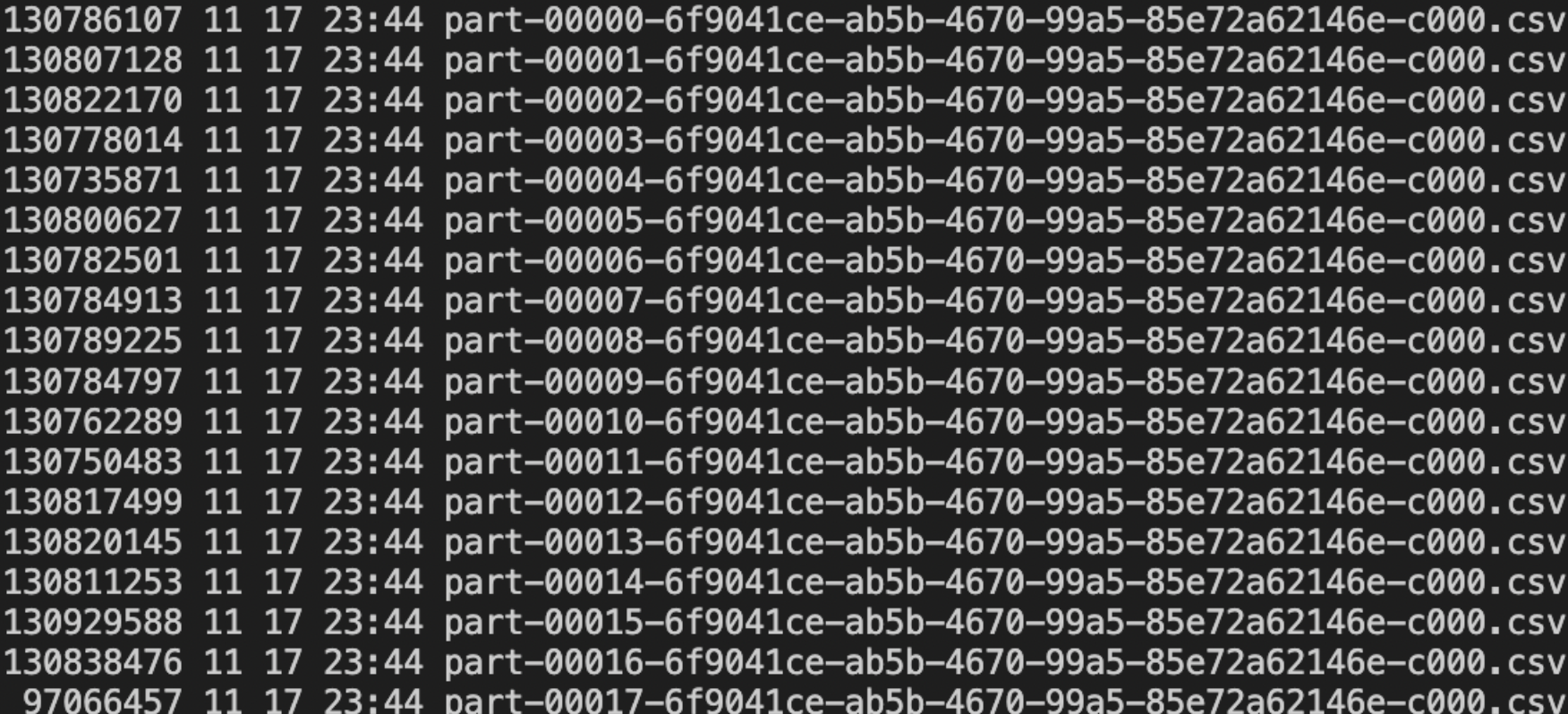
Beta이 글은 Spark에서 JDBC를 통해 RDB 데이터를 수집할 때 발생할 수 있는 병렬 처리 관련 주의 사항을 다룹니다. Spark은 JDBC 라이브러리를 사용하여 데이터를 읽을 수 있지만, 병렬 처리가 제대로 이루어지지 않으면 단일 태스크로 인해 대량 데이터 조회 시 timeout, OOM, Storage Spill 등의 문제가 발생할 수 있습니다.
이를 해결하기 위해 `partitionColumn`, `lowerBound`, `upperBound`, `numPartitions` 옵션을 활용하여 데이터를 여러 파티션으로 나누어 병렬 처리하는 방법을 설명합니다. 하지만 이 과정에서 `partitionColumn`의 카디널리티가 높을 경우 예상치 못한 파티션 Skew가 발생할 수 있음을 지적하며, 이에 대한 주의를 당부합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기