딥러닝 ‘생성모델’과 ‘잠재 벡터’에 관하여
딥러닝생성모델잠재 벡터LLM음성 합성영상 생성
AI 요약
Beta이 글은 AI 아나운서 제작에 활용된 딥러닝 생성 모델과 잠재 벡터의 역할에 대해 설명합니다. 과거 인식 분야에 집중되었던 딥러닝이 최근 음성 합성(TTS) 및 영상 생성 분야에서 방송 제작 수준으로 발전했음을 보여줍니다.
특히 이스트소프트 AI 연구소에서 개발한 AI 아나운서는 YTN 뉴스 방송에 실제 활용된 사례로 소개됩니다. 글은 기계학습 모델을 인식 모델과 생성 모델로 구분하며, 생성 모델이 고차원의 데이터를 생성하는 특징과 그 과정에서 다양성을 확보하는 것이 중요함을 강조합니다.
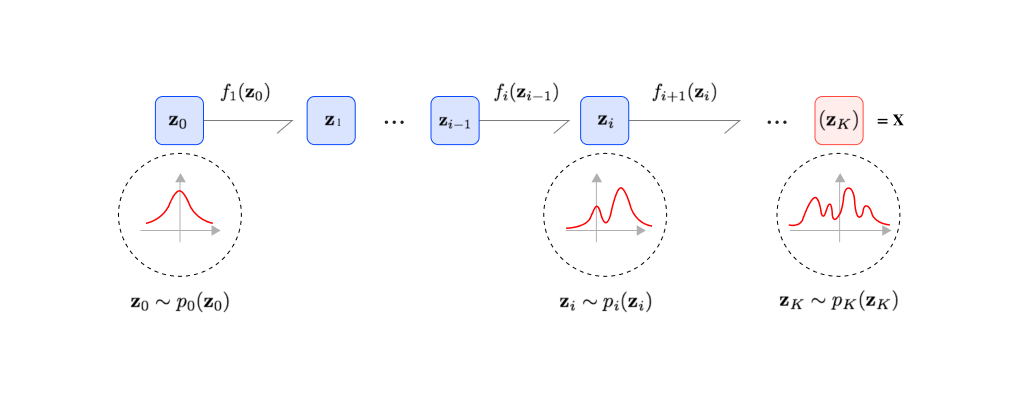
또한, 생성 모델 입문자를 위해 잠재 벡터의 개념과 역할을 소개하여 이해를 돕고자 합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기