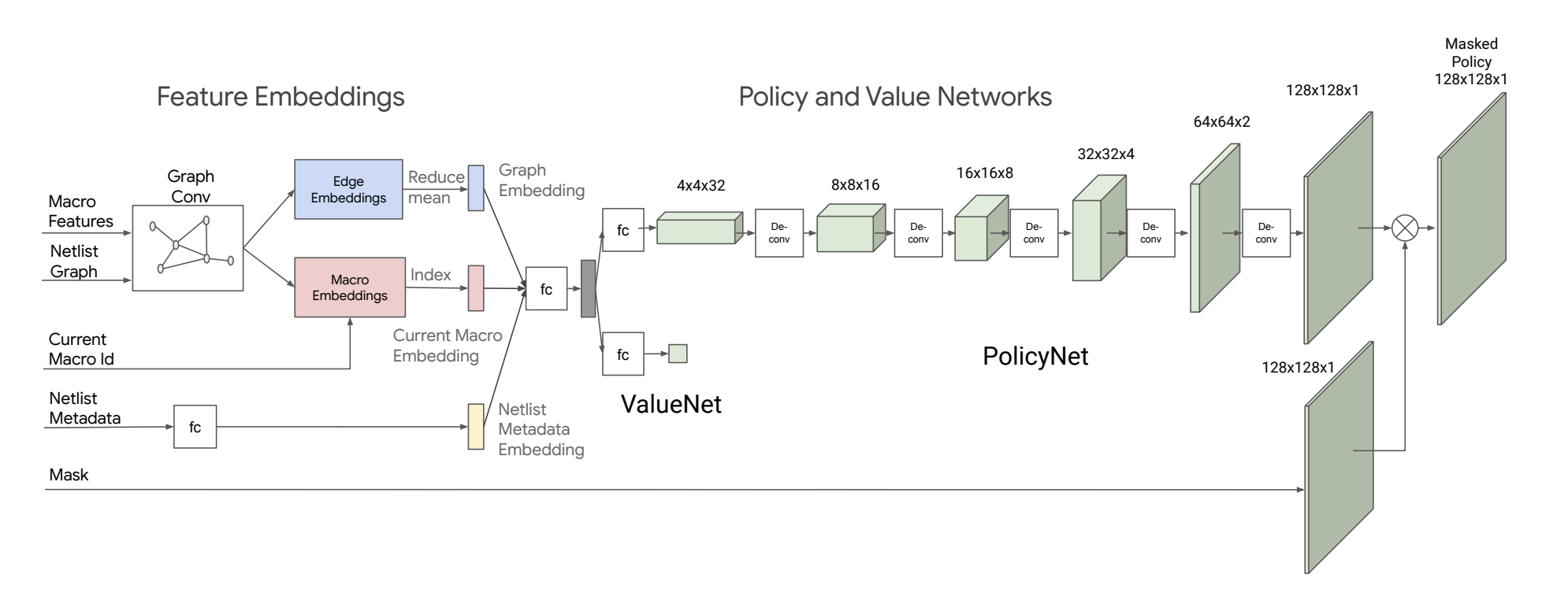
Neural Combinatorial Optimization with Reinforcement Learning
Neural Combinatorial OptimizationReinforcement Learning딥러닝Combinatorial OptimizationTraveling Salesman ProblemLLM
AI 요약
Beta본 포스팅은 딥러닝을 활용하여 조합 최적화 문제를 해결하는 연구 분야인 Neural Combinatorial Optimization을 소개합니다. 특히, 조합 최적화 문제 해결에 강화학습을 적용한 대표적인 연구를 다룹니다.
조합 최적화 문제는 유한한 탐색 공간에서 최적의 해를 찾는 문제로, 순회 세일즈맨 문제(TSP), 작업 공정 스케줄링, 배낭 문제 등이 있으며 대부분 NP-Hard 문제입니다. TSP는 주어진 노드를 모두 방문하고 시작점으로 돌아올 때 총 여행 거리를 최소화하는 순회 순서를 결정하는 문제로, 탐색 공간이 매우 커서 효율적인 해결책이 중요합니다.
본문에서는 이러한 조합 최적화 문제에 딥러닝과 강화학습을 접목하여 해결하려는 시도를 소개하고 있습니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기