카프카 커넥트를 데이터 파이프라인으로 사용하는 이유? kafka-sink-connector 오픈소스 언빡싱!
KafkaKafka Connect데이터 파이프라인ETL오픈소스로그 데이터
AI 요약
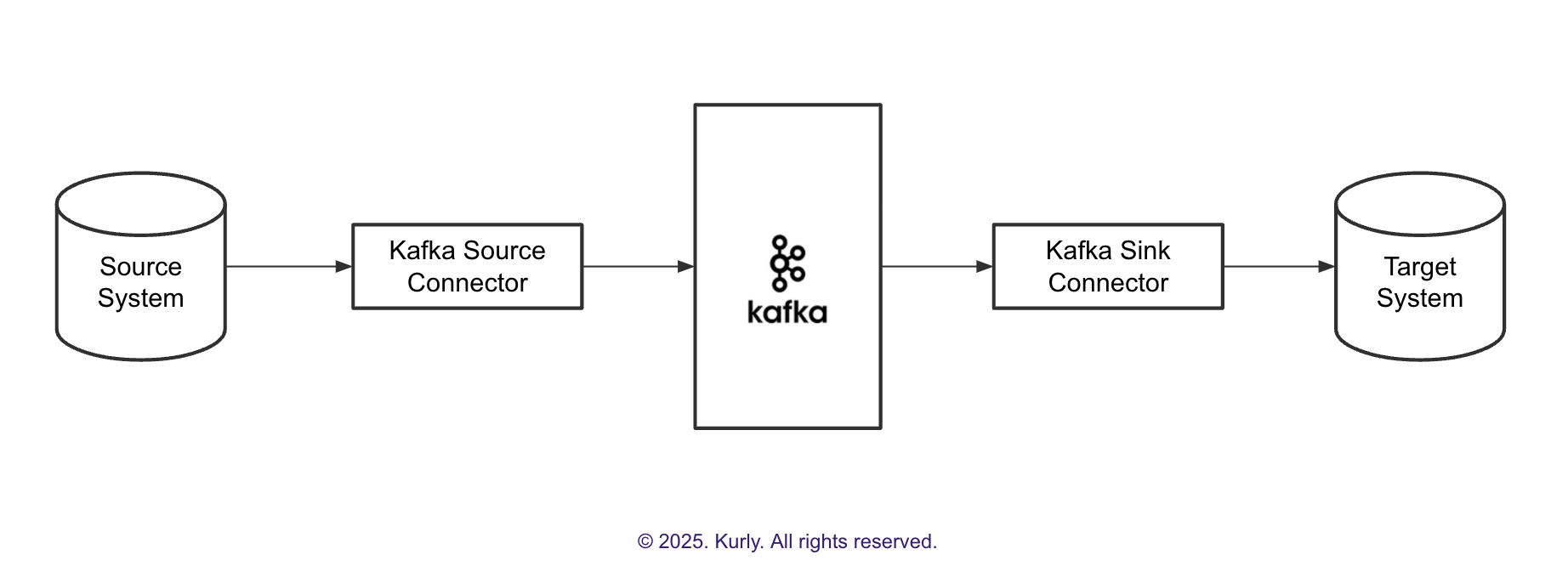
Beta이 글은 광고추천팀에서 카프카(Kafka) 기반 스트림 데이터 플랫폼을 운영하며 겪는 데이터 처리 과정과 `kafka-sink-connector` 오픈소스 활용 방안을 소개합니다. 광고 로그 데이터는 개인화 광고 서빙 및 모델 학습에 필수적이며, 이를 위해 카프카 기반의 데이터 플랫폼 '제네시스'를 운영하고 있습니다.
특히, 지면별로 분리되지 않는 방대한 양의 광고 스트림 데이터를 효율적으로 처리하기 위해 `kafka-sink-connector`를 커스텀 개발하여 사용하고 있습니다. 이 커넥터는 2023년 1월 오픈소스로 공개되어 누구나 자유롭게 사용할 수 있으며, 글에서는 이 커넥터의 개발 배경, 현재 팀에서의 활용 방법, 그리고 사용법을 간략하게 설명합니다.
이를 통해 대규모 스트림 데이터를 실시간으로 처리하고 분석하는 데 있어 `kafka-sink-connector`의 유용성을 강조합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기