LINE에서 Kafka를 사용하는 방법 – 1편
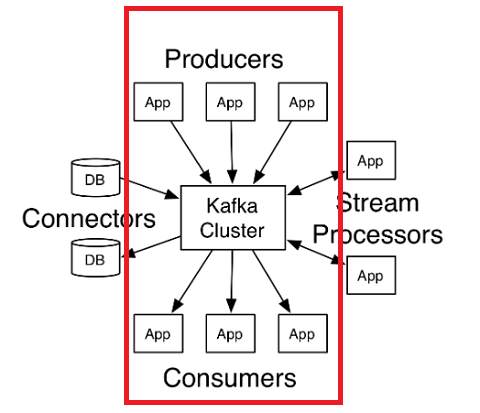
Kafka메시지 큐스트리밍 데이터Pub/SubBroker clusterProducerConsumer
AI 요약
BetaLINE에서 대규모 Kafka 플랫폼을 운영하는 방법에 대한 글입니다. Kafka는 높은 확장성, 가용성, 데이터 영속성, Pub/Sub 모델을 지원하는 스트리밍 데이터 미들웨어입니다.
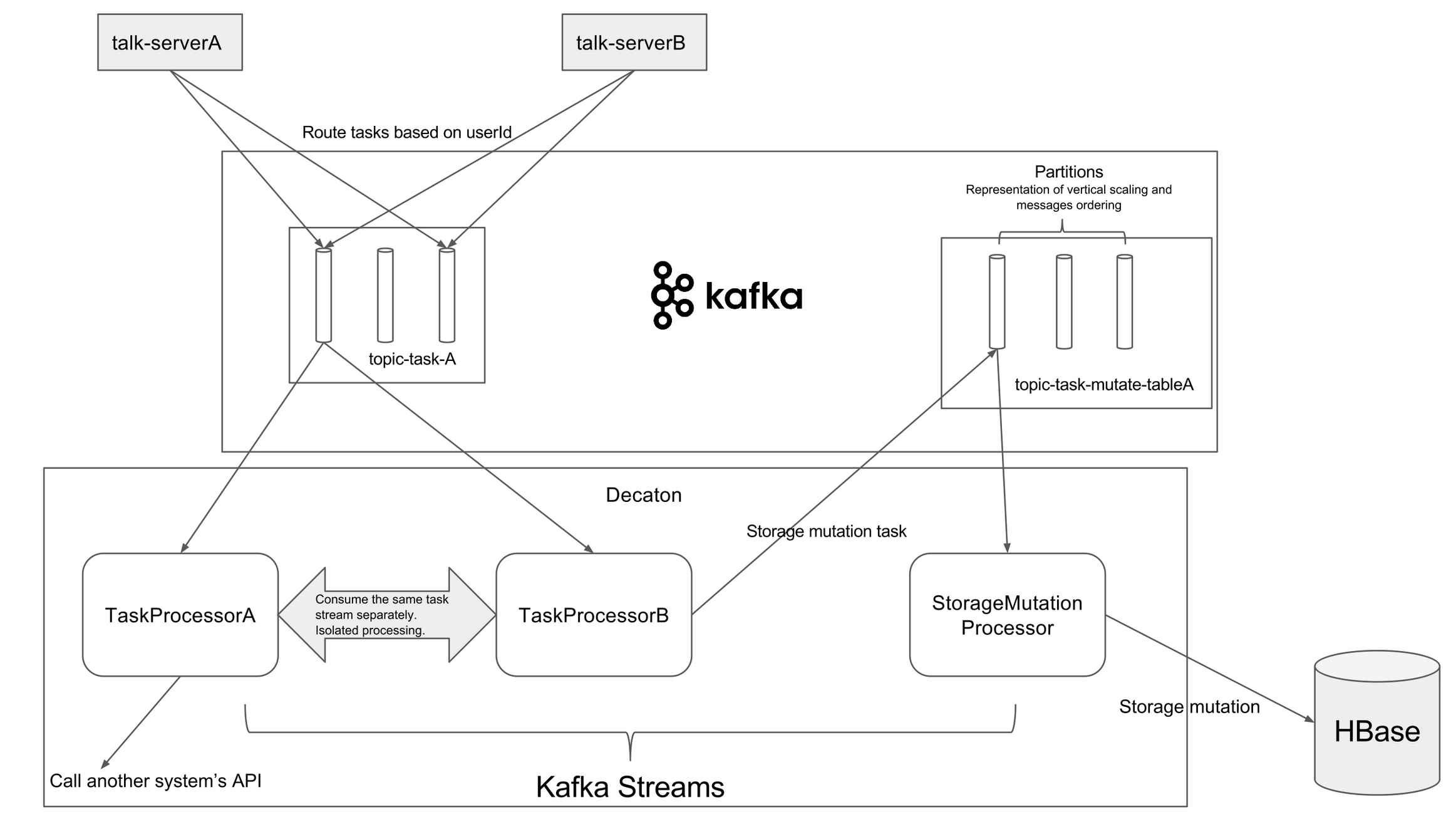
글에서는 Kafka의 핵심 컴포넌트인 Producer, Broker cluster, Consumer를 설명하며, Producer는 데이터를 Kafka에 입력하고, Broker cluster는 topic 단위로 데이터를 관리하며, Consumer는 topic에서 데이터를 가져와 각기 다른 목적으로 처리한다고 설명합니다. 특히 하나의 topic에 여러 Consumer가 존재하며 각기 다른 처리를 할 수 있다는 점을 강조합니다.
이 글은 LINE DEVELOPER DAY 2018 발표 내용을 기반으로 작성되었습니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기