LINE에서 Kafka를 사용하는 방법 – 2편
KafkaProduce API클러스터성능 저하디스크 읽기네트워크 스레드
AI 요약
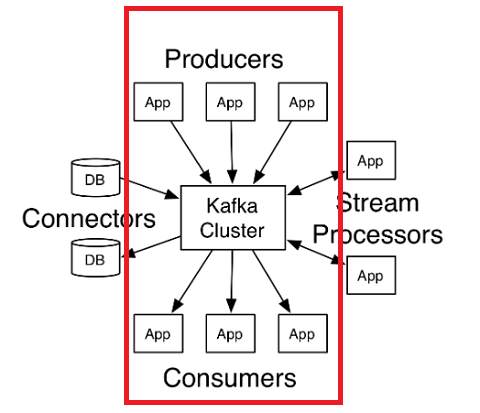
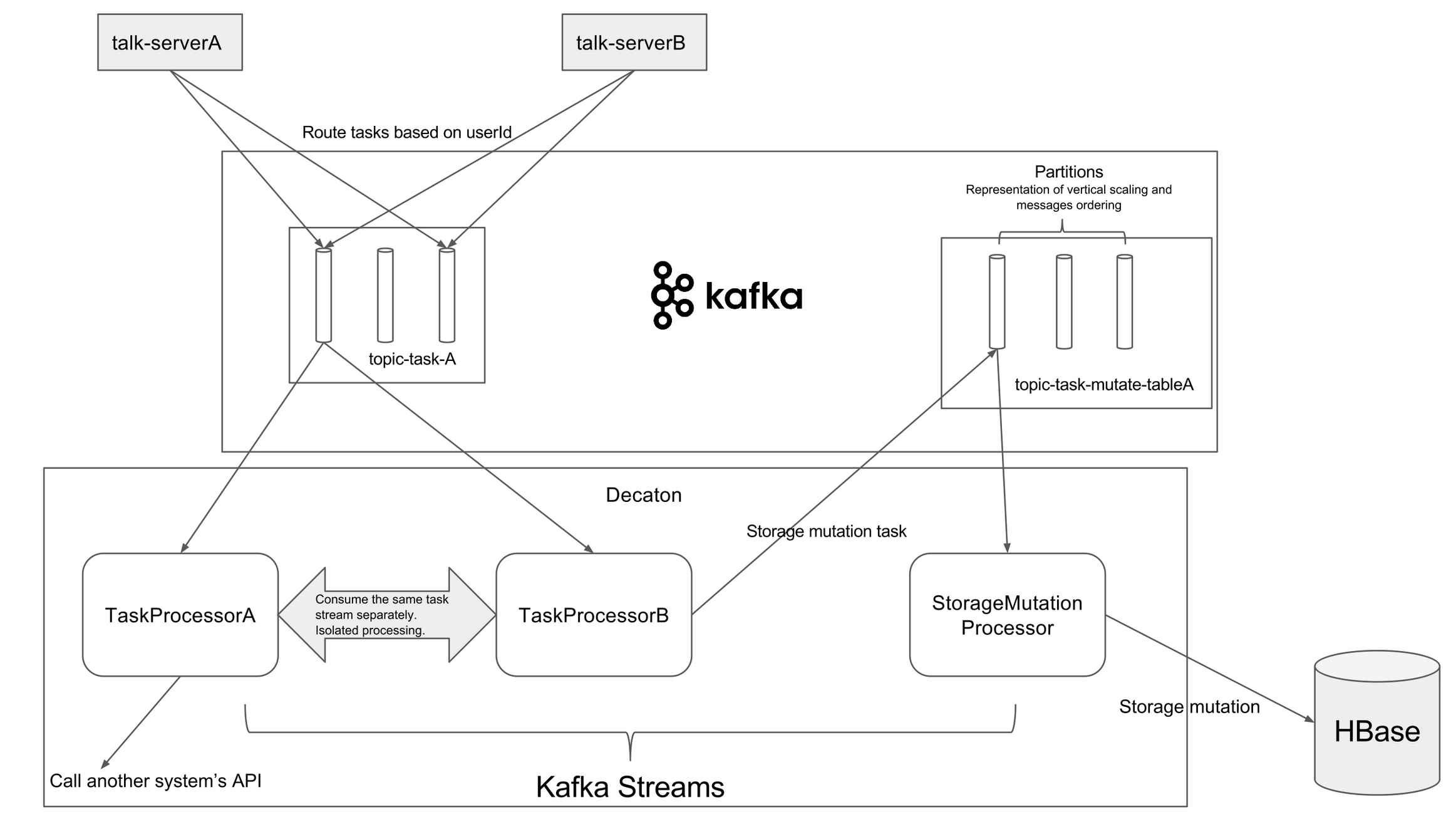
BetaLINE에서 Kafka를 사용하는 방법에 대한 2편 글로, 1편에 이어 Kafka 클러스터의 신뢰성과 성능 확보를 위한 클라이언트 작업 부하 격리 방안을 다룹니다. 실제 운영 환경에서 Produce API 응답 시간의 99번째 퍼센타일이 급격히 악화된 문제를 사례로 제시하며, 원인으로 브로커 기기의 과도한 디스크 읽기와 네트워크 스레드 이용률 급증을 지목합니다.
Kafka의 요청 처리 방식 중 네트워크 스레드가 클라이언트 I/O를 담당하며 요청을 처리하는 과정을 설명하고, 이러한 문제들이 어떻게 발생했는지 분석하는 내용을 담고 있습니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기