Data Parallelism in Machine Learning Training
Data Parallelism머신러닝생성형 AIDistributed TrainingGPU
AI 요약
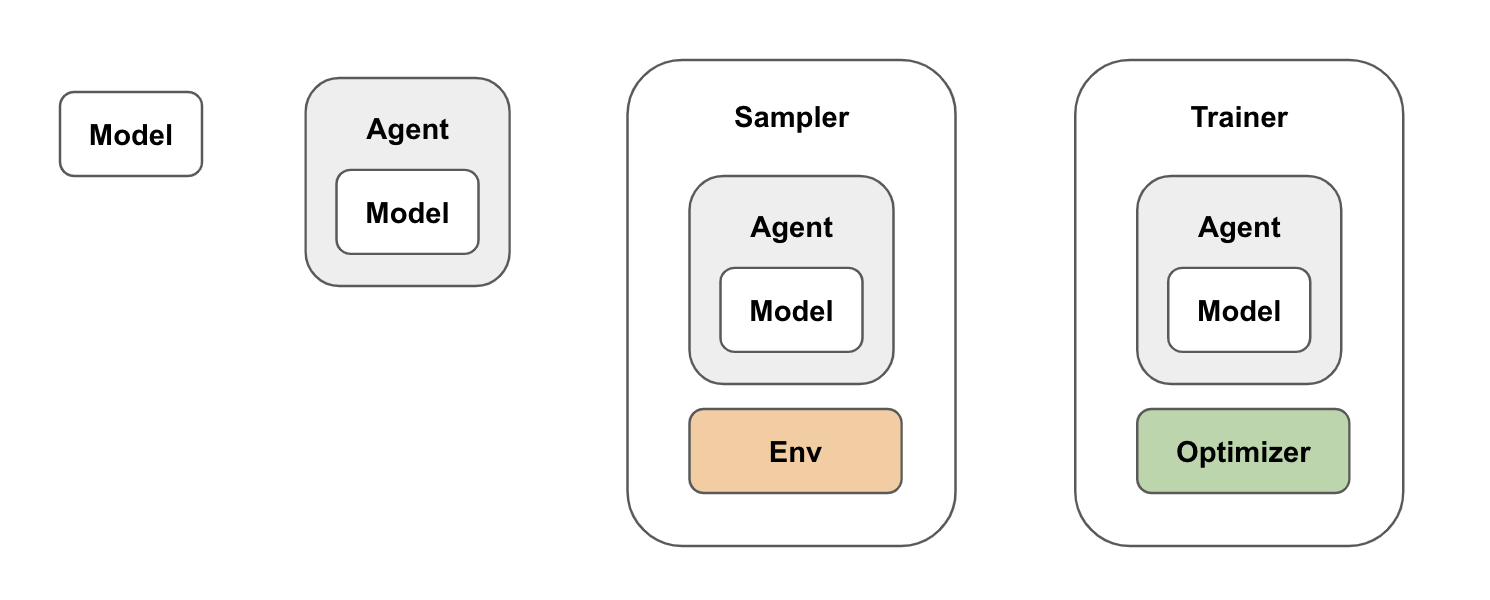
Beta이 글은 생성형 AI 시대에 필수적인 분산 학습 시스템의 핵심 개념인 데이터 병렬화(Data Parallelism)에 대해 설명합니다. 데이터 병렬화는 거대한 데이터셋을 여러 GPU에 분산시키고, 각 GPU는 모델의 복사본을 가지고 병렬적으로 학습하는 방식입니다.
각 GPU는 전체 데이터셋의 일부만 사용하여 모델을 학습하며, 학습 중 모델 상태를 동기적 또는 비동기적으로 업데이트하여 모든 GPU의 상태를 수렴시킵니다. 이는 대규모 AI 모델 학습의 효율성을 높이는 중요한 기법입니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기