한국 문화 이해부터 화면 조작까지: Kanana-V 기능 확장의 모든 것
VLM멀티모달 검색한국어PDF 이해GUI GroundingComputer Use Agent
AI 요약
Beta카카오 AI 모델 팀은 텍스트, 이미지, 음성을 이해하는 멀티모달 언어모델(VLM)의 기능 확장을 다룹니다. 특히 실제 서비스 환경에서 요구되는 PDF 문서 이해, 다중 이미지 분석, GUI 화면 인식 및 조작 능력 향상에 초점을 맞춥니다.
테라바이트 규모의 인터리브드 데이터셋 정제를 통한 한국어 문맥 이해 강화, 자체 구축한 한국어 PDF 벤치마크(KoPDFBench)를 활용한 PDF 이해 능력 향상, 다중 이미지 및 Long-Context 학습 최적화 과정을 상세히 공유합니다. 또한, Computer Use Agent(CUA)의 핵심 기술인 GUI Grounding 기술까지 소개하며, 실무에서 직면했던 문제와 해결 과정에서 얻은 인사이트를 제공합니다.
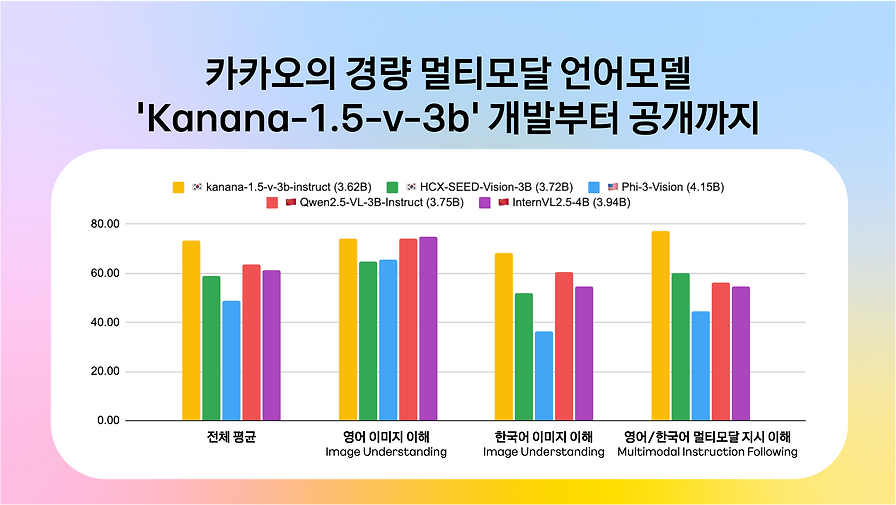
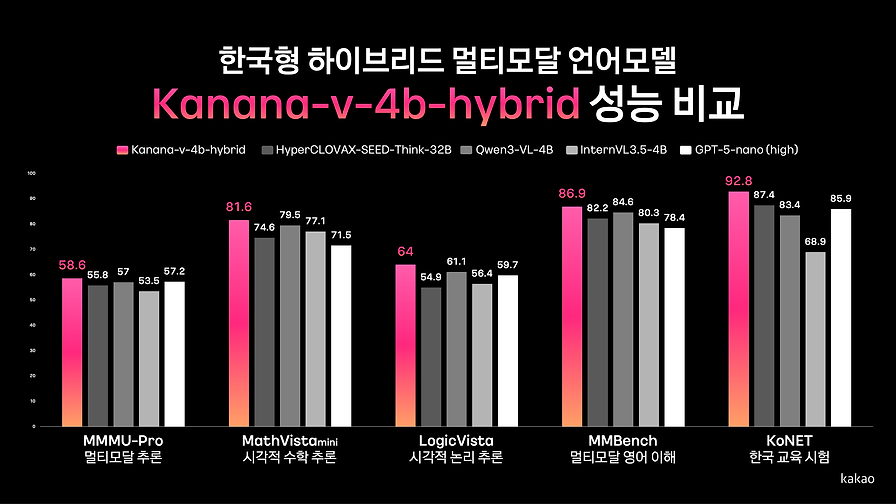
자체 벤치마크 결과, 글로벌 오픈소스 모델 대비 대등하거나 우수한 성능을 보였으며, 특히 한국어 특화 태스크에서 경쟁력을 확인했습니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기