이미지와 음성을 아우르는 카카오의 멀티모달 언어모델 Kanana-o 알아보기
멀티모달 언어모델Kanana-oKanana-aLLM음성 이해이미지 이해카카오
AI 요약
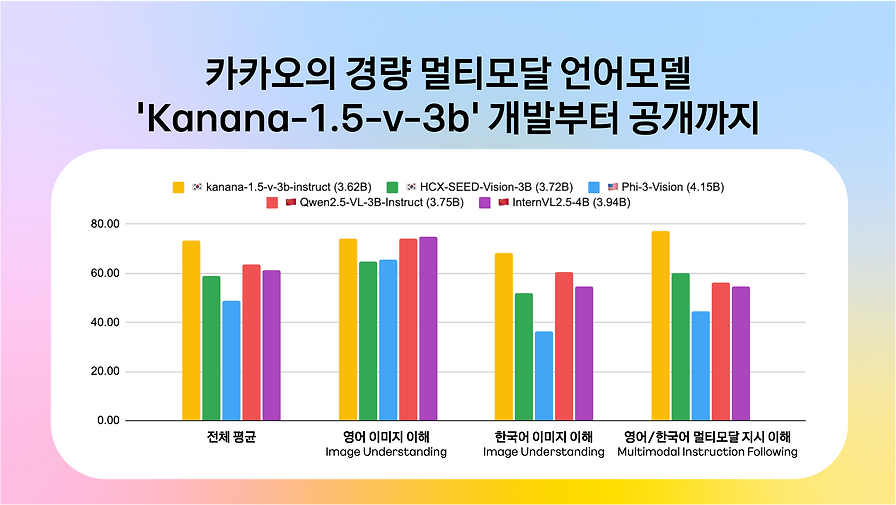
Beta카카오의 Kanana 조직은 텍스트, 이미지, 오디오를 모두 이해하는 멀티모달 언어모델 Kanana-o를 개발했습니다. Kanana-o는 이전에 소개된 이미지 이해 모델 Kanana-v와 텍스트 및 오디오 이해 모델 Kanana-a를 결합한 결과물입니다.
특히 Kanana-a는 음성의 비언어적 정보(말투, 속도, 억양 등)까지 파악하여 인간과 유사한 방식으로 소통하는 것을 목표로 합니다. Kanana-o는 모델 병합 기법과 자체 제작한 이미지-오디오 통합 데이터를 활용하여 학습 효율을 높였으며, 다양한 한국어 및 영어 벤치마크에서 글로벌 경쟁력을 입증했습니다.
본 글에서는 Kanana-a 개발 과정과 Kanana-o를 결합한 경험, 성능 결과 및 활용 예시를 소개합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기