Content clustering using word2vec
word2vec컨텐츠 클러스터링자연어 처리머신러닝임베딩LDATF-IDF
AI 요약
Beta버즈빌의 허니스크린 서비스는 사용자 경험 개선을 위해 질 좋은 콘텐츠를 적절한 사용자에게 제공하는 것이 중요합니다. 이를 위해 머신러닝 기반의 콘텐츠 클러스터링 작업에 집중하고 있으며, 두 가지 접근법을 사용합니다.
첫째는 콘텐츠 본문과 제목의 유사성을 측정하는 방식이고, 둘째는 사용자 클릭 이력을 기반으로 콘텐츠 유사성을 측정하는 방식입니다. 특히 자연어처리 기법 중 하나인 word2vec을 활용하여 콘텐츠 클러스터링의 효율성을 높이고자 합니다.
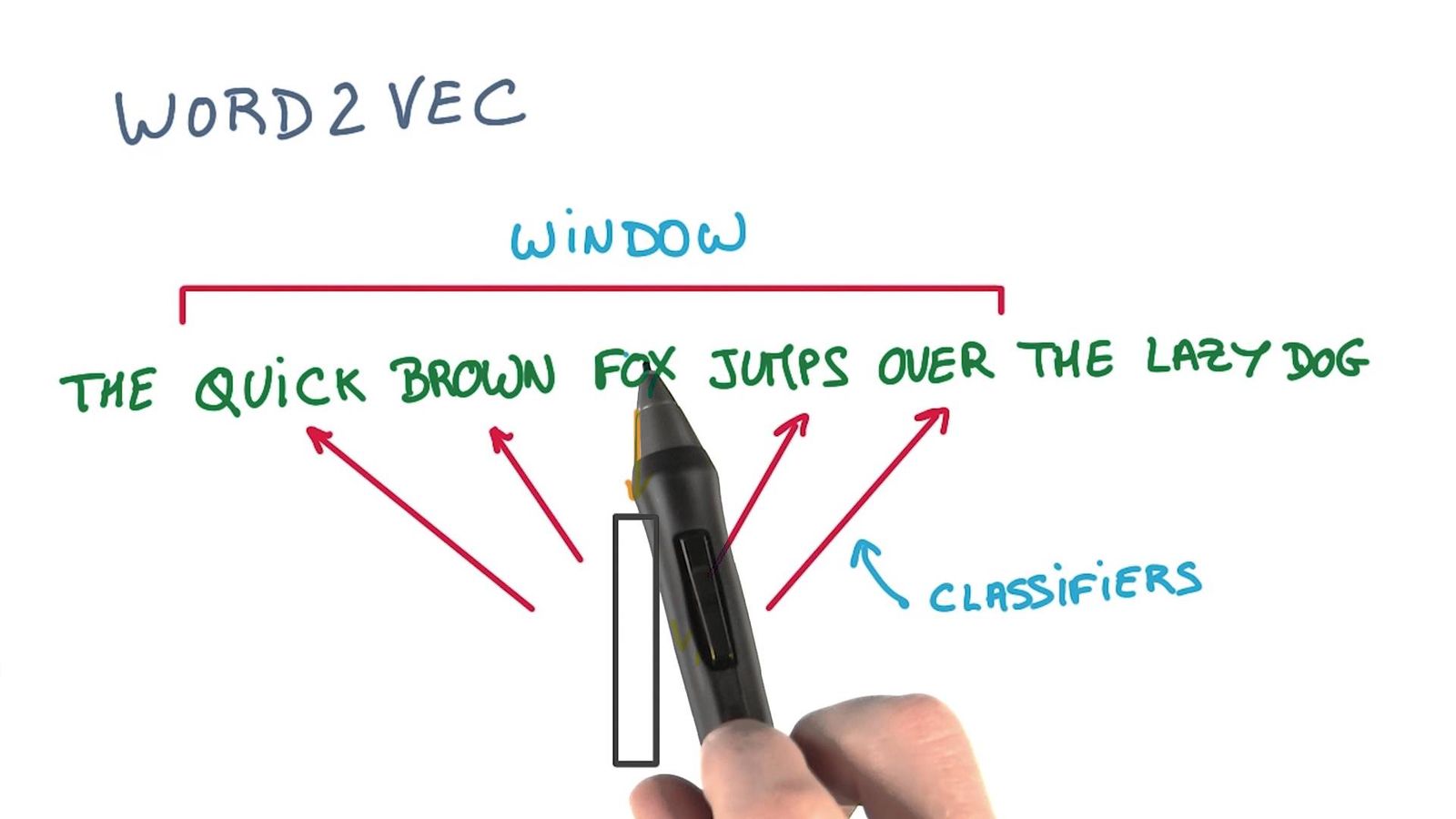
word2vec은 단어를 벡터 공간에 임베딩하여 단어를 표현하는 방식으로, 단어 벡터 간의 연산이 의미 있는 결과를 도출하는 특징이 있습니다. 이 글에서는 word2vec의 원리와 버즈빌에서의 활용 사례를 소개하며, LDA, TF-IDF 등 다른 자연어처리 기법도 함께 언급합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기