Self-supervised Learning on Billion Unlabeled Image Data 및 Full Stack Product - 연구결과(3)
Self-supervised LearningUnlabeled DataComputer VisionRepresentation LearningImage ClassificationLLM
AI 요약
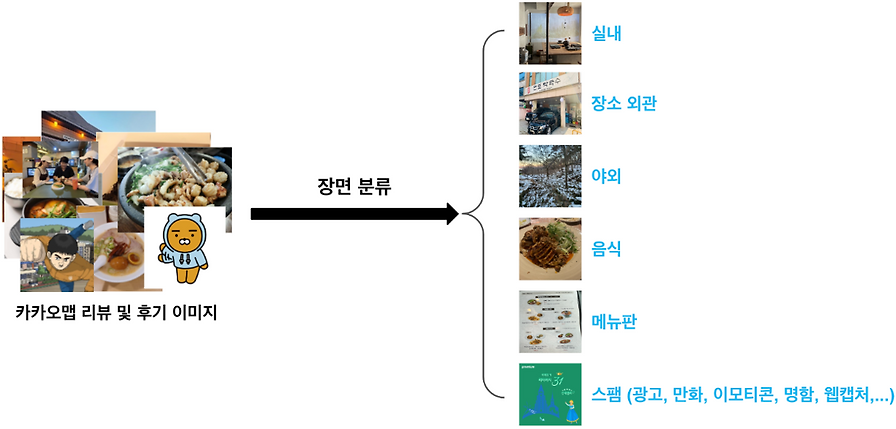
Beta본 글은 대규모의 레이블 없는 이미지 데이터를 활용하여 Self-supervised Learning 기법을 적용한 연구 결과를 공유합니다. 특히, 사내 차종 분류 태스크에 이 기법을 적용하여 기존의 ImageNet 사전 학습 모델의 한계를 극복하고 방대한 비정형 데이터를 활용하여 성능을 향상시키는 방안을 모색합니다.
연구팀은 public set과 veri-wild set에서의 실험을 거쳐 최종적으로 사내 실험 데이터셋에 적용한 과정과 결과를 상세히 기술합니다. 레이블 없는 데이터를 활용하여 기존 모델의 성능을 높이고자 하는 개발자나 특정 도메인에 맞는 Representation 학습에 대한 고민을 가진 연구자들에게 유용한 정보를 제공합니다.
LLM과 같은 최신 AI 기술 트렌드 속에서 이미지 데이터 활용의 새로운 가능성을 제시합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기