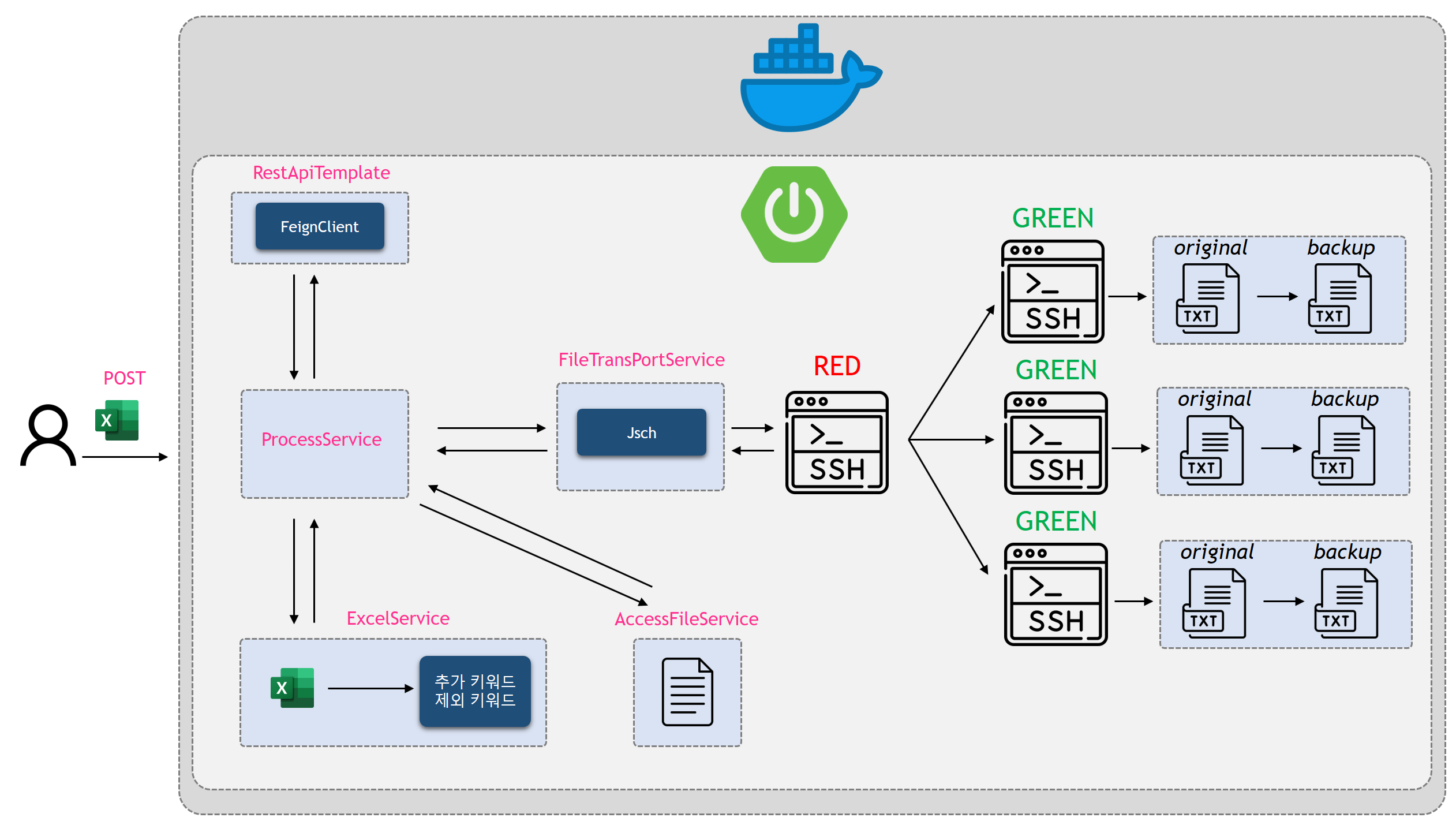
검색 데이터 서빙 플랫폼 구축
검색 엔진SolrKafkaAPI 서버데이터 파이프라인색인
AI 요약
Beta본 글은 검색 대상 문서에 대한 색인 및 서빙 플랫폼 구축 프로젝트를 소개합니다. 사용자의 검색 요청에 실시간으로 응답하는 검색 서비스를 제공하기 위해 Solr 검색 엔진 클러스터 구축, Kafka를 활용한 데이터 파이프라인 구축, 그리고 검색 API 서버 개발을 진행했습니다.
Solr 스키마 설계, 색인 필드 추출 및 가공, Kafka 클러스터를 통한 데이터 생산 및 소비, 그리고 기본 검색, 시간 범위 검색, 필터 검색 기능을 포함하는 API 서버 구축 과정을 상세히 다룹니다. Spring Boot, Kafka, Solr 등의 기술 스택을 활용하여 검색 서비스의 핵심 요구사항을 만족시키는 플랫폼을 성공적으로 구축한 경험을 공유합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기