AI-Text 필터링 모델을 위한 거대 ML 모델 적용기
AI-Text 필터거대 ML 모델LINENLP파인튜닝다국어 모델
AI 요약
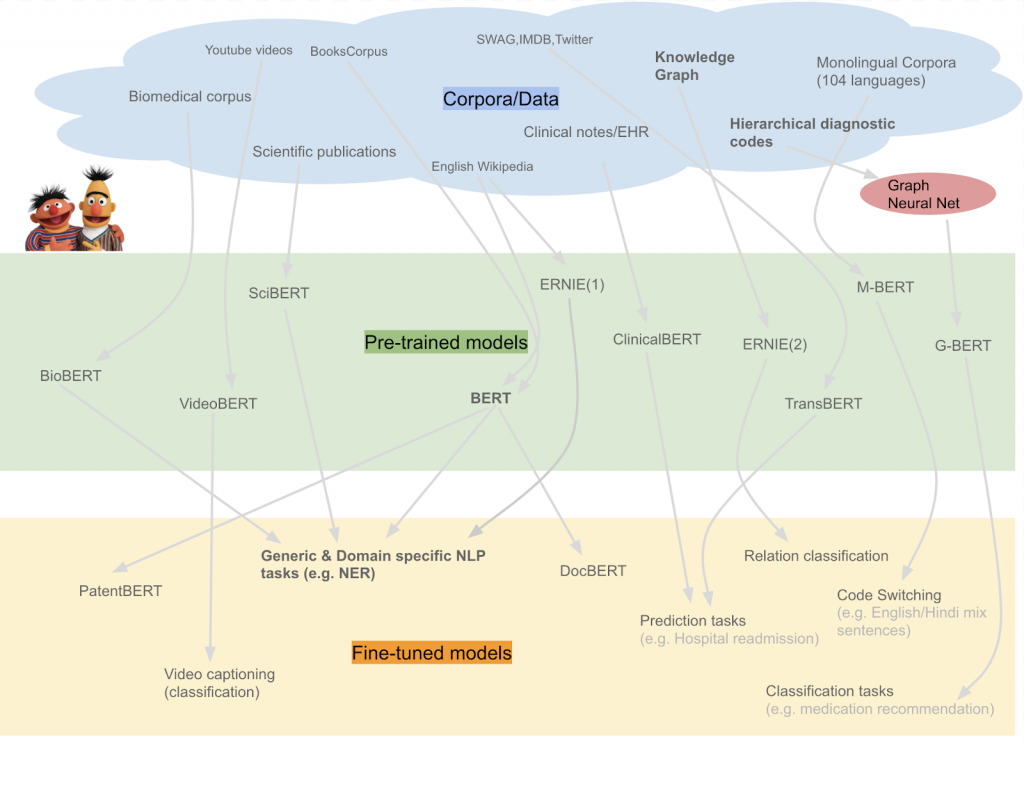
Beta이 글은 LINE의 NLP 엔지니어가 AI-Text 필터 모델의 성능 개선을 위해 거대 머신러닝 모델을 적용한 경험을 공유합니다. AI-Text 필터는 LINE 모니터링 시스템에서 사용자의 공개 문장을 일반 문장과 비일반 문장으로 분류하며, 월평균 3억 8천만 건의 문장을 처리합니다.
기존에는 단일 언어 사전 학습 모델을 파인튜닝하는 방식이었으나, 언어 변경 시 최적의 모델을 찾는 데 많은 비용이 들었습니다. 이를 해결하기 위해 다국어 모델을 도입하고, 스케일링 법칙에 따라 모델 크기를 늘려 성능을 향상시키는 거대 모델을 적용했습니다.
이 과정에서 다국어 모델의 성능 저하 문제를 극복하고 AI-Text 필터의 정확도를 높이는 방법을 다룹니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기