TwelveLabs Marengo를 활용한 Amazon Bedrock에서의 영상 이해 기술 구현
TwelveLabs MarengoAmazon Bedrock Agents영상 이해멀티모달 AI임베딩Vector DBAmazon OpenSearch Serverless
AI 요약
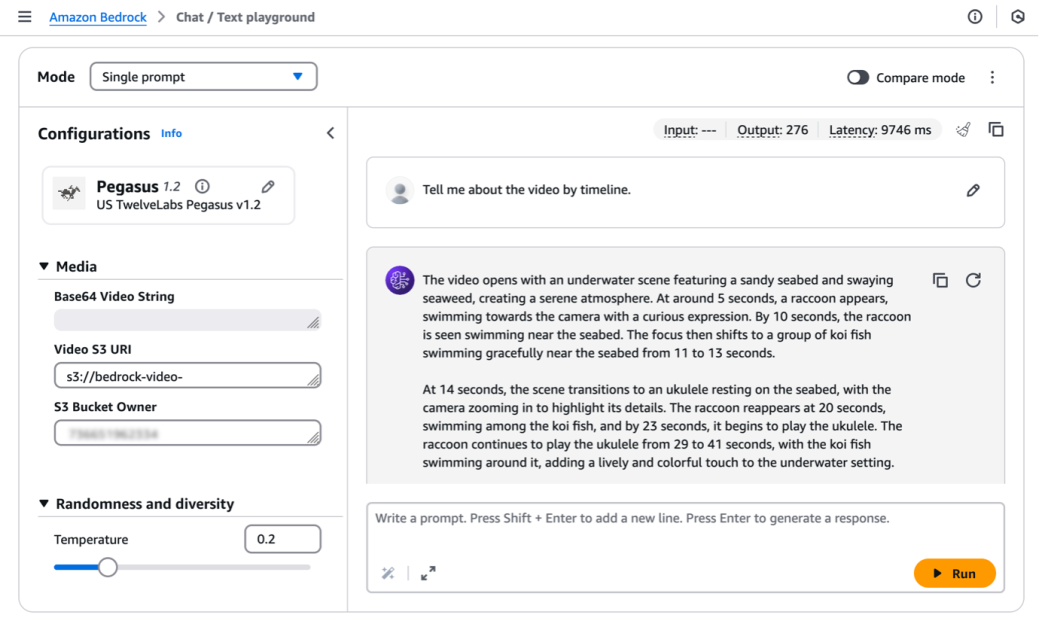
Beta이 글은 TwelveLabs Marengo 임베딩 모델을 Amazon Bedrock에서 활용하여 영상 이해 기술을 구현하는 방법을 설명합니다. 복잡한 비디오 콘텐츠의 시각, 청각, 동작 요소를 효과적으로 분석하기 위해, 각 모달리티별로 개별 임베딩을 생성하는 다중 벡터 아키텍처를 사용합니다.
이를 통해 비디오 데이터의 풍부한 특성을 유지하면서 정교한 분석이 가능해집니다. 0 모델을 통해 실시간 텍스트·이미지 처리를 지원하며, 자연어 질의 기반의 비디오 검색 및 인터랙티브 상품 탐색 경험을 구현할 수 있습니다.
또한, Amazon OpenSearch Serverless 벡터 데이터베이스와 함께 사용하여 단순 메타데이터 검색을 넘어선 지능형 콘텐츠 발견 솔루션을 구축하는 방안을 제시합니다. 데이터 검색을 넘어선 지능형 콘텐츠 발견 솔루션을 구축하는 방안을 제시합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기