Spark Streaming을 활용한 파생 데이터 생성 시간 감축 사례
Spark StreamingHiveOozieAirflowData PipelineBig Data
AI 요약
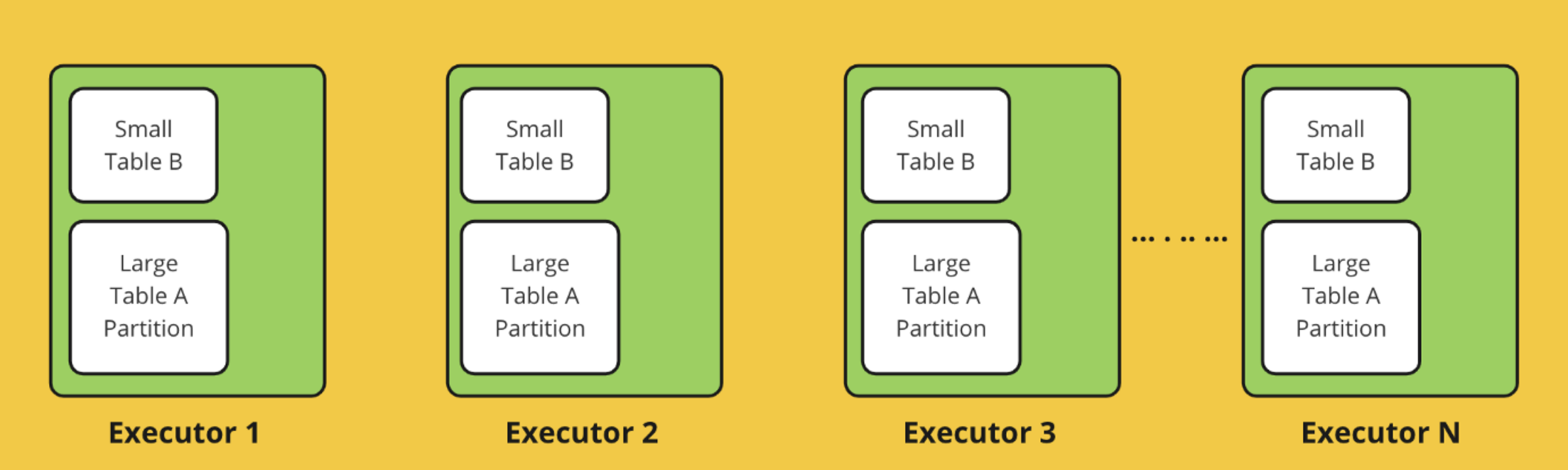
Beta이 글은 SK플래닛의 Hadoop 기반 빅데이터 시스템에서 파생 데이터 생성 지연 문제를 해결하기 위한 Spark Streaming 도입 사례를 다룹니다. 기존에는 Hive Query와 Oozie, Airflow를 이용한 배치 방식으로 파생 데이터를 생성하여 데이터 지연이 발생했지만, 이를 개선하기 위해 'Streaming Platform as a Service(SPaaS)' 개념을 도입하고 'Router'라는 서비스를 개발했습니다.
Router는 데이터 파이프라인을 시각화하고 Hive Query를 재사용하며, 실시간 데이터 처리를 통해 파생 데이터 생성 시간을 단축하는 것을 목표로 합니다. 이를 통해 데이터 분석 및 인사이트 도출의 신속성을 높이고 새로운 서비스 제공 지연을 해소할 수 있습니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기