How we pipe data
데이터 파이프라인데이터 수집Redshift데이터 스토리지데이터 분석
AI 요약
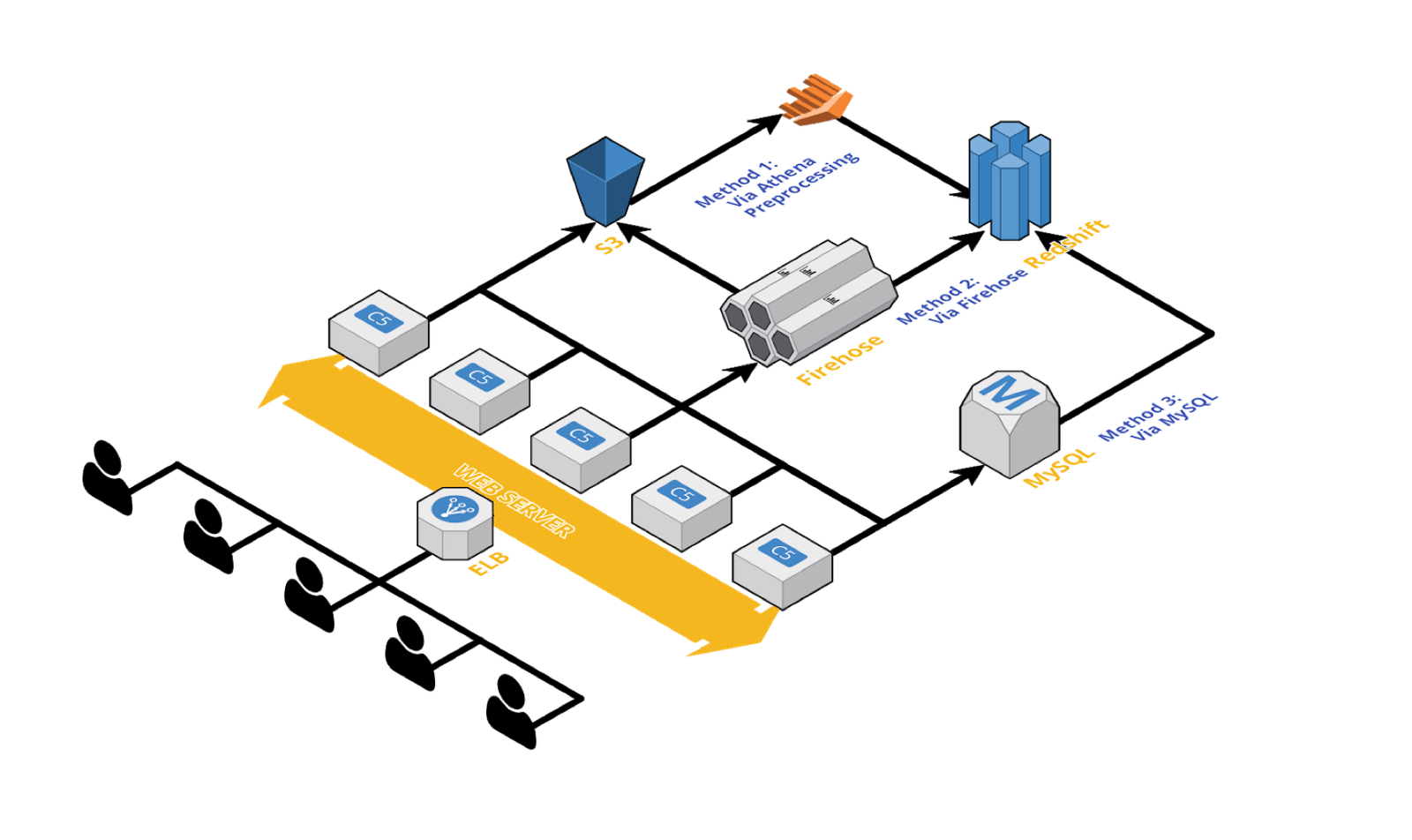
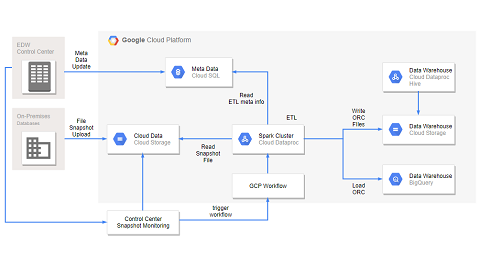
Beta버즈빌은 전 세계 30개국에서 1,700만 명 이상의 사용자 행동 데이터를 수집하고 있으며, 이 데이터는 다양한 소스와 데이터베이스(MySQL, DynamoDB, Redis, S3 등)에 분산되어 저장됩니다. 이러한 데이터를 분석하고 활용하기 위해, 다양한 소스에서 발생하여 여러 DB에 저장된 데이터를 한 곳으로 모으는 '데이터 파이프라인' 구축의 필요성을 느끼고 이를 계획했습니다.
이 글에서는 버즈빌이 데이터를 수집하고 통합하기 위해 구축한 데이터 파이프라인에 대해 공유합니다. 특히, 데이터 통합의 최종 목적지인 AWS Redshift를 선택한 이유와 그 특징(Column 기반 스토리지, 복잡한 쿼리 처리 용이성, 분산 저장, 빠른 데이터 수집, 수평적 확장성)에 대해 상세히 설명하며, 대규모 데이터 분석에 적합한 Redshift의 장점을 강조합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기