R벤치마크 - 데이터 불러오기
R데이터 불러오기대용량 데이터데이터 샘플링데이터 분석
AI 요약
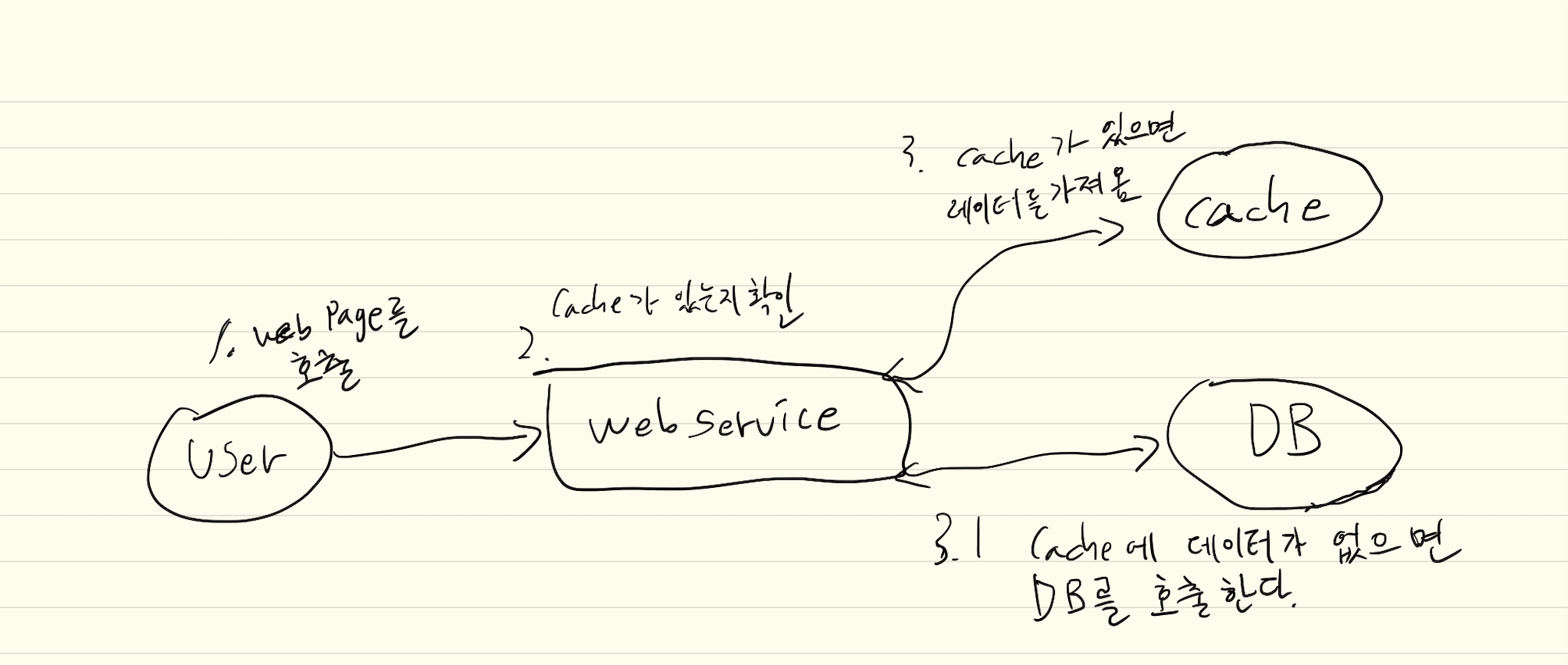
Beta이 글은 R을 사용하여 대용량 데이터를 효율적으로 불러오고 처리하는 방법에 대해 다룹니다. 데이터 과학과 경진대회 참여 증가로 인해 방대한 양의 데이터를 다루는 경우가 많아졌으며, 특히 딥러닝과 같이 데이터가 많을수록 성능이 향상되는 기법을 적용할 때 중요합니다.
데이터의 종류와 크기에 따라 다른 접근 방식이 필요하며, 사인펜과 스프레이 비유를 통해 효율성의 중요성을 설명합니다. 대용량 데이터를 처리하기 위한 첫 번째 해결책으로 '데이터 샘플링'을 제시합니다.
모든 데이터를 사용하기보다 무작위 추출 등의 샘플링 기법을 활용하면 적은 양의 데이터로도 대용량 데이터 분석과 유사한 결과나 성능을 얻을 수 있으며, 이는 추론 통계학의 근간이기도 합니다. 애자일 개발론처럼 작고 빠르게 시도해보는 샘플링 방식이 효율적임을 강조합니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기