Amazon Bedrock Knowledge Bases: 데이터 특성을 고려한 분할 전략으로 검색 성능 최적화하기
RAGAmazon Bedrock AgentsKnowledge Bases청킹CSVOpenSearch
AI 요약
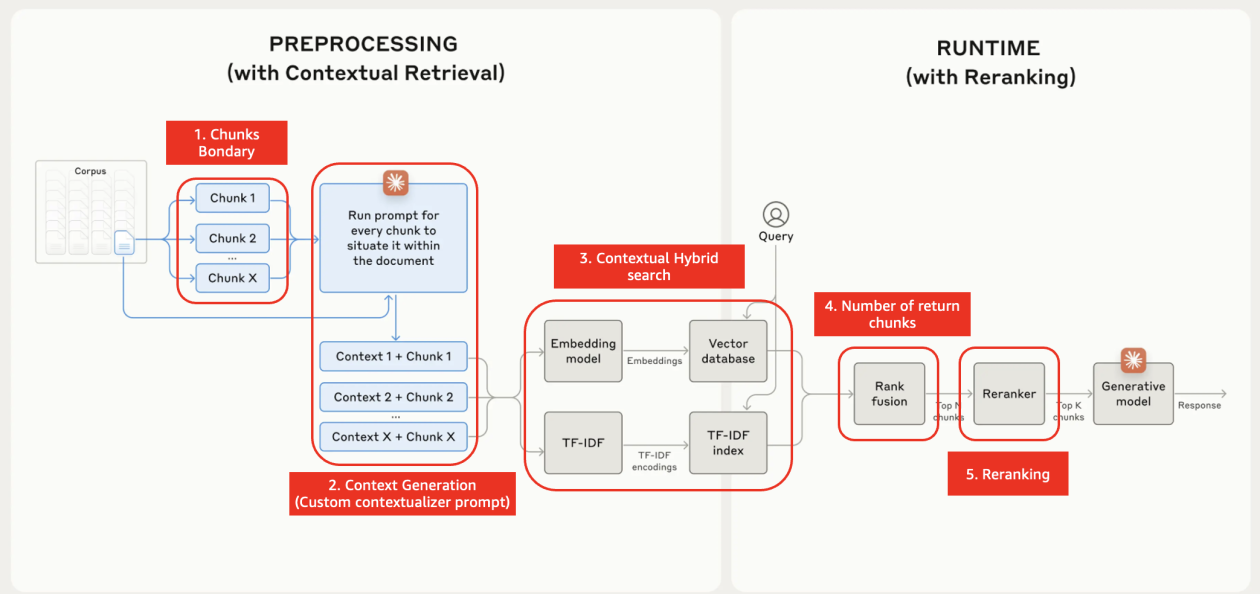
Beta본 글은 생성형 AI 기반 RAG 시스템에서 짧은 텍스트 데이터 처리 시 발생하는 기존 청킹 전략의 한계점을 지적하고, Amazon Bedrock Knowledge Bases를 활용한 최적화 방안을 제시합니다. FAQ, 팁 등 간결한 텍스트 데이터는 기존 청킹 방식에서 맥락 손실, 검색 정확도 저하, 토큰 비효율성 등의 문제를 야기할 수 있습니다.
이를 해결하기 위해 CSV 파일과 'No Chunking' 전략을 사용하여 각 텍스트 단위를 하나의 청크로 유지하고, 메타데이터를 활용하여 검색 맥락을 풍부하게 하는 방법을 소개합니다. 또한, OpenSearch Dashboard를 통해 데이터 구조를 검증하고 검색 정확도를 최적화하는 실습 내용을 다룹니다.
이 글이 궁금하신가요?
원문 블로그에서 전체 내용을 확인해 보세요
원문 읽으러 가기